Una base de datos es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso.
Se define una base de datos como una serie de datos organizados y relacionados entre sí, los cuales son recolectados y explotados por los sistemas de información de una empresa o negocio en particular.
– Regla 2: la regla del acceso garantizado, todos los datos deben ser accesibles sin ambigüedad. Dice que cada valor escalar individual en la base de datos debe ser lógicamente direccionable especificando el nombre de la tabla, la columna que lo contiene y la llave primaria.
– Regla 3: tratamiento sistemático de valores nulos, el sistema de gestión de base de datos debe permitir que haya campos nulos. Debe tener una representación de la “información que falta y de la información inaplicable” que es sistemática, distinto de todos los valores regulares.
– Regla 4:los usuarios deben poder tener acceso a la estructura de la base de datos (catálogo).
– Regla 5: el sistema debe soportar por lo menos un lenguaje relacional que:
-Tenga una sintaxis lineal.
-Puede ser utilizado de manera interactiva.
-Soporte operaciones de definición de datos, operaciones de manipulación de datos (actualización así como la recuperación), seguridad e integridad y operaciones de administración de transacciones.
-Cuando una versión distribuida del SGBD se introdujo por primera vez cuando se distribuyen los datos existentes se redistribuyen en todo el sistema.
– Regla 6: todas las vistas que son teóricamente actualizables deben ser actualizables por el sistema.
– Regla 7: alto nivel de inserción, actualización, y cancelación, el sistema debe soportar suministrar datos en el mismo tiempo que se inserte, actualiza o esté borrando. Esto significa que los datos se pueden recuperar de una base de datos relacional en los sistemas construidos de datos de filas múltiples y/o de tablas múltiples.
– Regla 8: independencia física de los datos, los programas de aplicación y actividades del terminal permanecen inalterados a nivel lógico cuando quiera que se realicen cambios en las representaciones de almacenamiento o métodos de acceso.
– Regla 9: independencia lógica de los datos, los cambios al nivel lógico (tablas, columnas, filas, etc.) no deben requerir un cambio a una solicitud basada en la estructura. La independencia de datos lógica es más difícil de lograr que la independencia física de datos.
– Regla 10: independencia de la integridad, las limitaciones de la integridad se deben especificar por separado de los programas de la aplicación y se almacenan en la base de datos. Debe ser posible cambiar esas limitaciones sin afectar innecesariamente las aplicaciones existentes.
– Regla 11: independencia de la distribución, la distribución de las porciones de la base de datos a las varias localizaciones debe ser invisible a los usuarios de la base de datos. Los usos existentes deben continuar funcionando con éxito:
– Regla 12: la regla de la no subversión, si el sistema proporciona una interfaz de bajo nivel de registro, a parte de una interfaz relacional, que esa interfaz de bajo nivel no se pueda utilizar para subvertir el sistema, por ejemplo: sin pasar por seguridad relacional o limitación de integridad. Esto es debido a que existen sistemas anteriormente no relacionales que añadieron una interfaz relacional, pero con la interfaz nativa existe la posibilidad de trabajar no relacionalmente.
Microsoft SQL Server
Es una base de datos desarrollada por Microsoft y solo tiene compatibilidad con sistemas Windows. Hay muchos perfiles expertos en SQL Server y no es de difícil adquisición. La integración con Microsoft Azure ha mejorado mucho su flexibilidad y rendimiento. Además permite administrar información de otros servidores mejorando su usabilidad.
Oracle
Oracle es una base de datos que puede correr en casi cualquier sistema operativo. De Oracle destaca la abundancia de perfiles con experiencia en esta tecnología y la gran cantidad de herramientas que hay para su administración y monitorización.
IBM DB2
Es la segunda base de datos más utilizada en entornos Unix/Linux después de Oracle. Es claramente un indiscutible ganador en Mainframe. Hay perfiles profesionales para DB2 pero no tanto como para Oracle. Por otro lado, el perfil de DB2 Mainframe no tiene por qué saber moverse en DB2 linux/unix.
Teradata
Destaca sobre los demás tipos de bases de datos por su capacidad de almacenamiento y de análisis de datos. Suele ser utilizado en grandes instalaciones de Big Data.
SAP Sybase
Hace una década fue una de las bases de datos con más éxito; hoy en día ya está menos extendida, pero sigue destacando por su escalabilidad y rendimiento.
Informix
Durante 1990, la empresa Informix fue un sistema de bases de datos muy popular. Sin embargo, en el año 2000 tuvo varios tropiezos en su gestión, debilitando a la compañía; finalmente vendió los derechos a IBM, incluyendo la marca, sus planes y la base de datos.
Se define una base de datos como una serie de datos organizados y relacionados entre sí, los cuales son recolectados y explotados por los sistemas de información de una empresa o negocio en particular.
Diferencia entre dato e información.
dato: es una respresentacion simbólica, un atributo o una característica de una entidad. Los datos describen hechos empíricos, sucesos y entidades.
Información: es el conjunto organizado de datos procesados, que constituyen un mensaje que cambia el estado de conocimiento del sujeto o sistema que recibe dicho mensaje.
12 Reglas de Codd
Regla 1: Toda la información en una base de datos relacional se representa explícitamente en el nivel lógico exactamente de una manera: con valores en tablas.– Regla 2: la regla del acceso garantizado, todos los datos deben ser accesibles sin ambigüedad. Dice que cada valor escalar individual en la base de datos debe ser lógicamente direccionable especificando el nombre de la tabla, la columna que lo contiene y la llave primaria.
– Regla 3: tratamiento sistemático de valores nulos, el sistema de gestión de base de datos debe permitir que haya campos nulos. Debe tener una representación de la “información que falta y de la información inaplicable” que es sistemática, distinto de todos los valores regulares.
– Regla 4:los usuarios deben poder tener acceso a la estructura de la base de datos (catálogo).
– Regla 5: el sistema debe soportar por lo menos un lenguaje relacional que:
-Tenga una sintaxis lineal.
-Puede ser utilizado de manera interactiva.
-Soporte operaciones de definición de datos, operaciones de manipulación de datos (actualización así como la recuperación), seguridad e integridad y operaciones de administración de transacciones.
-Cuando una versión distribuida del SGBD se introdujo por primera vez cuando se distribuyen los datos existentes se redistribuyen en todo el sistema.
– Regla 6: todas las vistas que son teóricamente actualizables deben ser actualizables por el sistema.
– Regla 7: alto nivel de inserción, actualización, y cancelación, el sistema debe soportar suministrar datos en el mismo tiempo que se inserte, actualiza o esté borrando. Esto significa que los datos se pueden recuperar de una base de datos relacional en los sistemas construidos de datos de filas múltiples y/o de tablas múltiples.
– Regla 8: independencia física de los datos, los programas de aplicación y actividades del terminal permanecen inalterados a nivel lógico cuando quiera que se realicen cambios en las representaciones de almacenamiento o métodos de acceso.
– Regla 9: independencia lógica de los datos, los cambios al nivel lógico (tablas, columnas, filas, etc.) no deben requerir un cambio a una solicitud basada en la estructura. La independencia de datos lógica es más difícil de lograr que la independencia física de datos.
– Regla 10: independencia de la integridad, las limitaciones de la integridad se deben especificar por separado de los programas de la aplicación y se almacenan en la base de datos. Debe ser posible cambiar esas limitaciones sin afectar innecesariamente las aplicaciones existentes.
– Regla 11: independencia de la distribución, la distribución de las porciones de la base de datos a las varias localizaciones debe ser invisible a los usuarios de la base de datos. Los usos existentes deben continuar funcionando con éxito:
– Regla 12: la regla de la no subversión, si el sistema proporciona una interfaz de bajo nivel de registro, a parte de una interfaz relacional, que esa interfaz de bajo nivel no se pueda utilizar para subvertir el sistema, por ejemplo: sin pasar por seguridad relacional o limitación de integridad. Esto es debido a que existen sistemas anteriormente no relacionales que añadieron una interfaz relacional, pero con la interfaz nativa existe la posibilidad de trabajar no relacionalmente.
Las reglas de Codd se utilizan como modelo para la realización de bases de datos así como para trabajar las BD relacionales, ya que con estas reglas se considera mas relacional una base de datos.
Que es un motor de base de datos
Se llama motor, a las herramientas que permiten comunicarse con la base de datos, ejecutan los procesos sobre las tablas y mantienen la integridad de los datos. El motor es quien interpreta y ejecuta las consultas, mantiene los indices, entre muchas otras cosas.
Que es un SGBD
es un conjunto de programas que permiten crear y mantener una Base de datos, asegurando su integridad, confidencialidad y seguridad. Por tanto debe permitir:
- Definir una base de datos: especificar tipos, estructuras y restricciones de datos.
- Construir la base de datos: guardar los datos en algún medio controlado por el mismo SGBD.
- Manipular la base de datos: realizar consultas, actualizarla, generar informes.
- Definir una base de datos: especificar tipos, estructuras y restricciones de datos.
- Construir la base de datos: guardar los datos en algún medio controlado por el mismo SGBD.
- Manipular la base de datos: realizar consultas, actualizarla, generar informes.
Bases de datos mas utilizadas.
Microsoft SQL Server
Es una base de datos desarrollada por Microsoft y solo tiene compatibilidad con sistemas Windows. Hay muchos perfiles expertos en SQL Server y no es de difícil adquisición. La integración con Microsoft Azure ha mejorado mucho su flexibilidad y rendimiento. Además permite administrar información de otros servidores mejorando su usabilidad.
Oracle
Oracle es una base de datos que puede correr en casi cualquier sistema operativo. De Oracle destaca la abundancia de perfiles con experiencia en esta tecnología y la gran cantidad de herramientas que hay para su administración y monitorización.
IBM DB2
Es la segunda base de datos más utilizada en entornos Unix/Linux después de Oracle. Es claramente un indiscutible ganador en Mainframe. Hay perfiles profesionales para DB2 pero no tanto como para Oracle. Por otro lado, el perfil de DB2 Mainframe no tiene por qué saber moverse en DB2 linux/unix.
Teradata
Destaca sobre los demás tipos de bases de datos por su capacidad de almacenamiento y de análisis de datos. Suele ser utilizado en grandes instalaciones de Big Data.
SAP Sybase
Hace una década fue una de las bases de datos con más éxito; hoy en día ya está menos extendida, pero sigue destacando por su escalabilidad y rendimiento.
Informix
Durante 1990, la empresa Informix fue un sistema de bases de datos muy popular. Sin embargo, en el año 2000 tuvo varios tropiezos en su gestión, debilitando a la compañía; finalmente vendió los derechos a IBM, incluyendo la marca, sus planes y la base de datos.
Clasificación de base de datos según variabilidad
Bases de datos estáticas
Son bases de datos únicamente de lectura, utilizadas principalmente para almacenar datos históricos que posteriormente se pueden utilizar para estudiar el comportamiento de un conjunto de datos a través del tiempo, realizar proyecciones, tomar decisiones y realizar análisis de datos para inteligencia empresarial.
Bases de datos dinámicas
Son bases de datos donde la información almacenada se modifica con el tiempo, permitiendo operaciones como actualización, borrado y edición de datos, además de las operaciones fundamentales de consulta. Un ejemplo, puede ser la base de datos utilizada en un sistema de información de un supermercado.
Modelos de base de datos
Un modelo de datos es básicamente una "descripción" de algo conocido como contenedor de datos (algo en donde se guardan los datos), así como de los métodos para almacenar y recuperar datos de esos contenedores. Los modelos de datos no son cosas físicas: son abstracciones que permiten la implementación de un sistema eficiente de base de datos; por lo general se refieren a algoritmos, y conceptos matemáticos.
Bases de datos jerárquicas
En este modelo los datos se organizan en forma de árbol invertido (algunos dicen raíz), en donde un nodo padre de información puede tener varios hijos. El nodo que no tiene padres es llamado raíz, y a los nodos que no tienen hijos se los conoce como hojas.
Las bases de datos jerárquicas son especialmente útiles en el caso de aplicaciones que manejan un gran volumen de información y datos muy compartidos permitiendo crear estructuras estables y de gran rendimiento.
Una de las principales limitaciones de este modelo es su incapacidad de representar eficientemente la redundancia de datos.
Base de datos de red
Este es un modelo ligeramente distinto del jerárquico; su diferencia fundamental es la modificación del concepto de nodo: se permite que un mismo nodo tenga varios padres (posibilidad no permitida en el modelo jerárquico).
Fue una gran mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente al problema de redundancia de datos; pero, aun así, la dificultad que significa administrar la información en una base de datos de red ha significado que sea un modelo utilizado en su mayoría por programadores más que por usuarios finales.
Bases de datos documentales
Permiten la indexación a texto completo, y en líneas generales realizar búsquedas más potentes, sirven para almacenar grandes volúmenes de información de antecedentes históricos. Tesaurus es un sistema de índices optimizado para este tipo de bases de datos.
Bases de datos relacionales
Su idea fundamental es el uso de "relaciones". Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados "tuplas". Pese a que esta es la teoría de las bases de datos relacionales creadas por Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar. Esto es pensando en cada relación como si fuese una tabla que está compuesta por registros (las filas de una tabla), que representarían las tuplas, y campos (las columnas de una tabla).
En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar para un usuario esporádico de la base de datos. La información puede ser recuperada o almacenada mediante "consultas" que ofrecen una amplia flexibilidad y poder para administrar la información.
Bases de datos orientadas a objetos
Una base de datos orientada a objetos es una base de datos que incorpora todos los conceptos importantes del paradigma de objetos.
En bases de datos orientadas a objetos, los usuarios pueden definir operaciones sobre los datos como parte de la definición de la base de datos. Una operación (llamada función) se especifica en dos partes. La interfaz (o signatura) de una operación incluye el nombre de la operación y los tipos de datos de sus argumentos (o parámetros). La implementación (o método) de la operación se especifica separadamente y puede modificarse sin afectar la interfaz. Los programas de aplicación de los usuarios pueden operar sobre los datos invocando a dichas operaciones a través de sus nombres y argumentos, sea cual sea la forma en la que se han implementado. Esto podría denominarse independencia entre programas y operaciones.
Que es una relación y que tipos existen
Las relaciones de bases de datos son asociaciones entre tablas que se crean utilizando sentencias de unión para recuperar datos.
| Tipo de relación | Descripción |
|---|---|
| Unívoca |
Las dos tablas pueden tener sólo un registro en cada lado de la relación.
Cada valor de clave primaria se relaciona con sólo un (o ningún) registro en la tabla relacionada.
La mayoría de relaciones unívocas están impuestas por las reglas empresariales y no fluyen con naturalidad a partir de los datos. Sin este tipo de regla, generalmente podrá combinar ambas tablas sin incumplir ninguna regla de normalización.
|
| Uno a varios | La tabla de claves primaria sólo contiene un registro que se relaciona con ninguno, uno o varios registros en la tabla relacionada. |
| Varios a varios | Cada registro en ambas tablas puede estar relacionado con varios registros (o con ninguno) en la otra tabla. Estas relaciones requieren una tercera tabla, denominada tabla de enlace o asociación, porque los sistemas relacionales no pueden alojar directamente la relación. |
Diseño de bases de datos
La fase de diseño conceptual tiene como objetivo crear un esquema conceptual de alto nivel e independiente de la tecnología a partir de los requisitos, las especificaciones y las restricciones que se han recogido en la fase anterior.
Los esquemas conceptuales describen conocimiento y, por tanto, son modelos de alto nivel y no incluyen detalles de implementación. un esquema conceptual, ademas debe servir de referencia para verificar que se han agrupado todos los requisitos y que no hay ningún conflicto entre ellos.

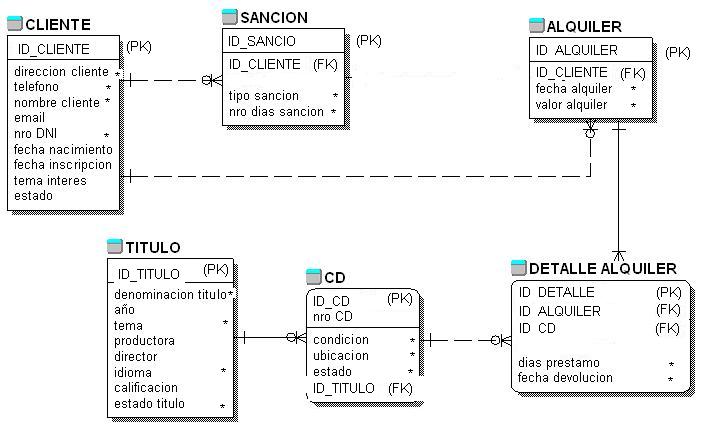
En la fase de diseño lógico se transforma el modelo conceptual, independiente del modelo de datos que se utilizara en la base de datos, en un modelo lógico dependiente del modelo de datos (o tipo SGBD) en el que se implementara la base de datos.
La transformación traducirá el modelo considerando el tipo de SGBD en le que se quiere implementar la base de datos. Por ejemplo, si se quiere crear la base de datos en un sistema relacional, esta etapa obtendrá un conjunto de relaciones con sus atributos, claves primarias y claves foráneas correspondientes.
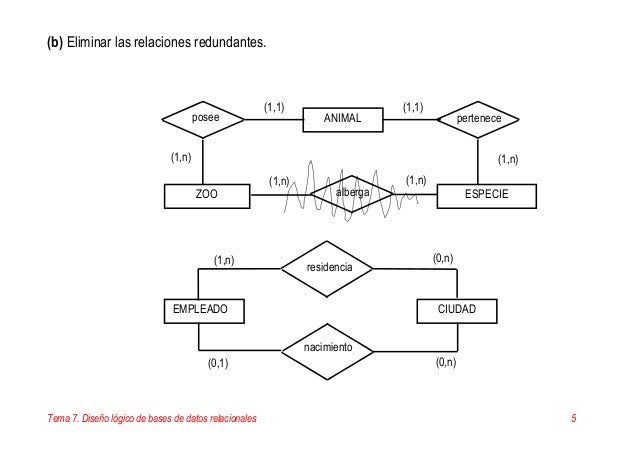
El diseño físico de una base de datos es un proceso que, a partir de un diseño lógico y de una estimación sobre el uso esperado de los datos de la base de datos, creara una configuración física de la base de datos adaptada al entorno donde se alojara y que permita el almacenamiento y la explotación de los datos con un rendimiento adecuado.
Son estructuras encargadas de alojar la información de la base de datos.
La transformación traducirá el modelo considerando el tipo de SGBD en le que se quiere implementar la base de datos. Por ejemplo, si se quiere crear la base de datos en un sistema relacional, esta etapa obtendrá un conjunto de relaciones con sus atributos, claves primarias y claves foráneas correspondientes.
El diseño físico de una base de datos es un proceso que, a partir de un diseño lógico y de una estimación sobre el uso esperado de los datos de la base de datos, creara una configuración física de la base de datos adaptada al entorno donde se alojara y que permita el almacenamiento y la explotación de los datos con un rendimiento adecuado.
Ventajas y Desventajas de las BD relacionales
- Ventajas
- Provee herramientas que garantizan evitar la duplicidad de registros.
- Garantiza la integridad referencial, así, al eliminar un registro elimina todos los registros relacionados dependientes.
- Favorece la normalización por ser más comprensible y aplicable.
- Desventajas
- Presentan deficiencias con datos gráficos, multimedia, CAD y sistemas de información geográfica.
- No se manipulan de forma manejable los bloques de texto como tipo de dato.
- Las bases de datos orientadas a objetos (BDOO) se propusieron con el objetivo de satisfacer las necesidades de las aplicaciones anteriores y así, complementar pero no sustituir a las bases de datos relacionales.
Elementos de una base de datos Relacional.
- TABLAS:
Son estructuras encargadas de alojar la información de la base de datos.
- CAMPOS:
Son cada una de las columnas de una tabla, cada campo almacena un dato en concreto.
- REGISTROS:
Cada una de las filas de la tabla que agrupa toda la información de un mismo elemento.
- RELACIONES:
Son los vínculos establecidos entre as diferentes tablas que permiten trabajar con los datos de todas ellas, como si estuvieran en una sola.
- CONSULTA:
Mediante el uso de consulta se puede extraer información concreta aunque la misma provenga de varias tablas.
Normalización
El proceso de normalización de bases de datos consiste en designar y aplicar una serie de reglas a las relaciones obtenidas tras el modelo entidad-relación.
Las bases de datos relacionales se normalizan para:
- Evitar la redundancia de los datos.
- Disminuir problemas de actualización de los datos en las tablas.
- Proteger la integridad de los datos.
Para que las tablas de nuestra BD estén normalizadas deben cumplir las siguientes reglas:
- Cada tabla debe tener su nombre único.
- No puede haber dos filas iguales.
- No se permiten los duplicados.
- Todos los datos en una columna deben ser del mismo tipo.
Existen 3 niveles de normalización que deben respetarse para poder decir que nuestra BDs, se encuentra NORMALIZADA, es decir, que cumple con los requisitos naturales para funcionar optima mente y no perjudicar el rendimiento por mala arquitectura.
Primera Forma Normal:
NO repetir campos en las tablas (atributos atómicos).
ALUMNOS
| alumno_id | alumno_nombre | estudio_nivel | estudio_nombre | materia |
|---|---|---|---|---|
| 1 | Juanito | Maestría | Medios Virtuales | MySQL |
| 1 | Juanito | Maestría | Medios Virtuales | PHP |
| 2 | Pepito | Licenciatura | Diseño Digital | MySQL |
| 2 | Pepito | Licenciatura | Diseño Digital | PHP |
Al aplicar la primer forma normal hemos generado un identificado para cada alumno y un registro por materia asignada, hemos duplicado información, sin embargo hemos conservado la integridad de las columnas de la información lo que es más óptimo que el modelo anterior, sin embargo podemos mejorarlo con la segunda forma normal.
Segunda Forma Normal:
Se debe aplicar la 1FN. Cada campo de la tabla debe depender de una clave única, si tuviéramos alguna columna que se repite a lo largo de todos los registros, dichos datos deberían atomizarse en una nueva tabla.
ALUMNOS
| alumno_id | alumno_nombre | estudio_nivel | estudio_nombre |
|---|---|---|---|
| 1 | Juanito | Maestría | Medios Virtuales |
| 2 | Pepito | Licenciatura | Diseño Digital |
MATERIAS
| materia_id | alumno_id | materia_nombre |
|---|---|---|
| 1 | 1 | MySQL |
| 2 | 1 | PHP |
| 3 | 2 | MySQL |
| 4 | 2 | PHP |
Al aplicar la segunda forma normal, hemos evitado la duplicación de registros y hemos separado la información de los alumnos de la relación que guardan con las materias generando una segunda tabla, sin embargo dicha tabla puede mejorarse con la tercer forma normal o su versión mejorada la forma de Boyce-Codd.
Tercera Forma Normal:
Se debe aplicar la 1FN y 2FN. Los campos que NO son clave NO deben tener dependencias.
Formas Normales
En la teoría de bases de datos relacionales, las formas normales (NF) proporcionan los criterios para determinar el grado de vulnerabilidad de una tabla a inconsistencias y anomalías lógicas. Cuanto más alta sea la forma normal aplicable a una tabla, menos vulnerable será a inconsistencias y anomalías. Cada tabla tiene una "forma normal más alta" (HNF): por definición, una tabla siempre satisface los requisitos de su HNF y de todas las formas normales más bajas que su HNF; también por definición, una tabla no puede satisfacer los requisitos de ninguna forma normal más arriba que su HNF.
SQL
SQL (por sus siglas en inglés Structured Query Language; en español lenguaje de consulta estructurada) es un lenguaje específico del dominio utilizado en programación, diseñado para administrar, y recuperar información de sistemas de gestión de bases de datos relacionales. Una de sus principales características es el manejo del álgebra y el cálculo relacional para efectuar consultas con el fin de recuperar, de forma sencilla, información de bases de datos, así como realizar cambios en ellas.
DDL
Un lenguaje de base de datos o lenguaje de definición de datos (Data Definition Language, DDL por sus siglas en inglés) es un lenguaje proporcionado por el sistema de gestión de base de datos que permite a los programadores de la misma llevar a cabo las tareas de definición de las estructuras que almacenarán los datos así como de los procedimientos o funciones que permitan consultarlos.
Un Data Definition Language o Lenguaje de descripción de datos ( DDL ) es un lenguaje de programación para definir estructura de datos . El término DDL fue introducido por primera vez en relación con el modelo de base de datos CODASYL, donde el esquema de la base de datos ha sido escrito en un lenguaje de descripción de datos que describe los registros, los campos, y "conjuntos" que conforman el usuario modelo de datos. Más tarde fue usado para referirse a un subconjunto de SQL, pero ahora se utiliza en un sentido genérico para referirse a cualquier lenguaje formal para describir datos o estructuras de información, como los esquemas XML.
DML
Lenguaje de Manipulación de Datos (Data Manipulation Language, DML) es un lenguaje proporcionado por los sistemas gestores de bases de datos que permite a los usuarios de la misma llevar a cabo las tareas de consulta o modificación de los datos contenidos en las Bases de Datos del Sistema Gestor de Bases de Datos.
SELECT
La sintaxis básica de select es la siguiente utilizando el estándar de SQL:
select columna from tabla;
Insert
La estructura básica para la sentencia insert utilizando el estándar de SQL es la siguiente:
insert into usuario (nombre, apellidos, edad, carrera) values ("Martín", "Bastida Godínez", "23", "Ingeniería en TI");
Tomando como ejemplo si se tuviera una tabla llamada 'usuario' con los campos de tipo cadena de caracteres (nombre, apellidos, edad, carrera), donde se inserta los valores que se encuentran en después de la palabra values, los valores se insertan en el orden correspondiente a como se hizo la llamada de los campos, los valores van separados por comas, las comillas dobles indican que se está insertando datos de tipo cadena de caracteres.
Delete
Para eliminar los registros de una tabla usamos el comando "delete":
delete from usuarios;
La ejecución del comando indicado en la línea anterior borra TODOS los registros de la tabla.
Si queremos eliminar uno o varios registros debemos indicar cuál o cuáles, para ello utilizamos el comando "delete" junto con la clausula "where" con la cual establecemos la condición que deben cumplir los registros a borrar. Por ejemplo, queremos eliminar aquel registro cuyo nombre de usuario es 'Martín':
delete from usuarios where nombre='Martín';
Si solicitamos el borrado de un registro que no existe, es decir, ningún registro cumple con la condición especificada, no se borrarán registros, pues no encontró registros con ese dato.
Update
Para modificar uno o varios datos de uno o varios registros utilizamos "update" (actualizar).
Por ejemplo, en nuestra tabla "usuarios", queremos cambiar los valores de todas las claves, por "Sevilla":
update usuarios set clave='Sevilla';
Utilizamos "update" junto al nombre de la tabla y "set" junto con el campo a modificar y su nuevo valor.
El cambio afectará a todos los registros.
DCL
Un Lenguaje de Control de Datos (DCL por sus siglas en inglés: Data Control Language) es un lenguaje proporcionado por el Sistema de Gestión de Base de Datos que incluye una serie de comandos SQL que permiten al administrador controlar el acceso a los datos contenidos en la Base de Datos.
Algunos ejemplos de comandos incluidos en el DCL son los siguientes:
- GRANT: Permite dar permisos a uno o varios usuarios o roles para realizar tareas determinadas.
- REVOKE: Permite eliminar permisos que previamente se han concedido con GRANT.
Las tareas sobre las que se pueden conceder o denegar permisos son las siguientes:
- CONNECT
- SELECT
- INSERT
- UPDATE
- DELETE
- USAGE
En Oracle, la ejecución de un comando DCL implica un COMMIT de forma implícita. Sin embargo, en PostgreSQL, la ejecución de un comando DCL forma parte de una transacción, por lo que puede ser deshecha mediante el comando ROLLBACK.
TCL
Tcl (pronunciado /tí.quel/, originado del acrónimo en inglés "Tool Command Language" o "lenguaje de herramientas de comando", actualmente se escribe como "Tcl" en lugar de "TCL"), es un lenguaje de script creado por John Ousterhout, que ha sido concebido con una sintaxis sencilla para facilitarse su aprendizaje, sin detrimento de la funcionalidad y expresividad.
Se utiliza principalmente para el desarrollo rápido de prototipos, aplicaciones "script", interfaces gráficas y pruebas. La combinación de Tcl con Tk (del inglés Tool Kit) es conocida como Tcl/Tk, y se utiliza para la creación de interfaces gráficas.
ACID
En bases de datos se denomina ACID a las características de los parámetros que permiten clasificar las transacciones de los sistemas de gestión de bases de datos. Cuando se dice que es ACID compliant se indica -en diversos grados- que éste permite realizar transacciones.
En concreto ACID es un acrónimo de Atomicity, Consistency, Isolation and Durability: Atomicidad, Consistencia, Aislamiento y Durabilidad en español.
- Atomicidad: Si cuando una operación consiste en una serie de pasos, bien todos ellos se ejecutan o bien ninguno, es decir, las transacciones son completas.
- Consistencia: (Integridad). Es la propiedad que asegura que sólo se empieza aquello que se puede acabar. Por lo tanto se ejecutan aquellas operaciones que no van a romper las reglas y directrices de Integridad de la base de datos. La propiedad de consistencia sostiene que cualquier transacción llevará a la base de datos desde un estado válido a otro también válido. "La Integridad de la Base de Datos nos permite asegurar que los datos son exactos y consistentes, es decir que estén siempre intactos, sean siempre los esperados y que de ninguna manera cambian ni se deformen. De esta manera podemos garantizar que la información que se presenta al usuario será siempre la misma."
- Aislamiento: Esta propiedad asegura que una operación no puede afectar a otras. Esto asegura que la realización de dos transacciones sobre la misma información sean independientes y no generen ningún tipo de error. Esta propiedad define cómo y cuándo los cambios producidos por una operación se hacen visibles para las demás operaciones concurrentes. El aislamiento puede alcanzarse en distintos niveles, siendo el parámetro esencial a la hora de seleccionar SGBDs.
- Durabilidad: (Persistencia). Esta propiedad asegura que una vez realizada la operación, esta persistirá y no se podrá deshacer aunque falle el sistema y que de esta forma los datos sobrevivan de alguna manera.
Cumpliendo estos 4 requisitos un sistema gestor de bases de datos puede ser considerado ACID Compliant.
CLOUD COMPUTING
De una manera simple, la computación en la nube (cloud computing) es una tecnología que permite acceso remoto a softwares, almacenamiento de archivos y procesamiento de datos por medio de Internet, siendo así, una alternativa a la ejecución en una computadora personal o servidor local. En el modelo de nube, no hay necesidad de instalar aplicaciones localmente en computadoras.
La computación en la nube ofrece a los individuos y a las empresas la capacidad de un pool de recursos de computación con buen mantenimiento, seguro, de fácil acceso y bajo demanda.
Comentarios
Publicar un comentario